Drag-and-drop kreering af Visual Studios strongly typed datasets.
ADO.NET er en særdeles fleksibel - ja fremragende!! - teknologi til implementation af database tilgang. Men ikke alle anvendelser af ADO.NET er af det gode ? visse anvendelser kan i værste fald medføre en dårlig arkitektur, hvor koden er svær at vedligeholde. Visual Studio har en feature, som man som udvikler bør holde sig fra. Da en del udviklere rent faktisk benytter denne feature, vil jeg i denne artikel begrunde, hvorfor man er bedst tjent med at holde sig fra den. Viden om udvikling af gode softwarearkitekturer handler i vidt omfang trods alt også om at vide, hvad man ikke skal gøre.
En guide til besnærende simpelt design af database tilgang:
- Start Visual Studio .NET.
- Start et nyt "Windows Application"-projekt i VB.NET eller C# alt efter præference.
- Find en passende database tabel i "Server Explorer" - f.eks. Servers | dinMaskinesNavn | SQL Servers | dinMaskinesNavn | pubs | Tables | authors. Træk denne tabel ind på design fladen af Form1. Der tilføjes herved to objekter til "komponent-kassen" som er at finde under formens egentlige designflade. De to objekter er dels et objekt af typen System.Data.SqlClient.SqlConnection (med navnet SqlConnection1) dels et objekt af typen System.Data.SqlClient.SqlDataAdapter (med navnet SqlDataAdapter1) [figur 1].
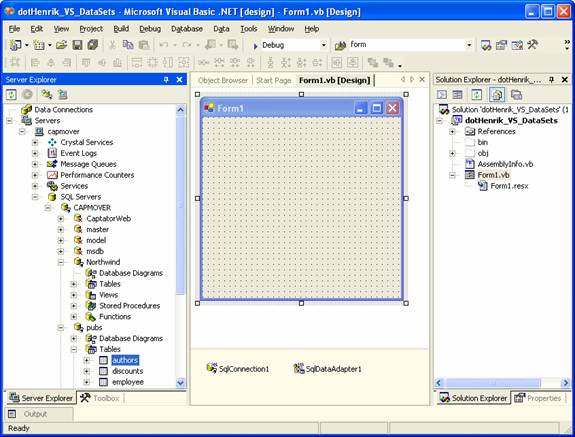
Figur 1: SqlConnection1 og SqlDataAdapter1 oprettes.
- Højreklik på SqlDataAdapter1. Vælg menupunktet "Generate Dataset...".
- Klik ok - med de default settings som fremgår af figur 2. Der bliver dels tilføjet et objekt af typen System.Data.DataSet (med navnet DataSet11 - læses formelt set som DataSet et-et) til "komponent-kassen", dels bliver filen DataSet1.xsd føjet til projektet.
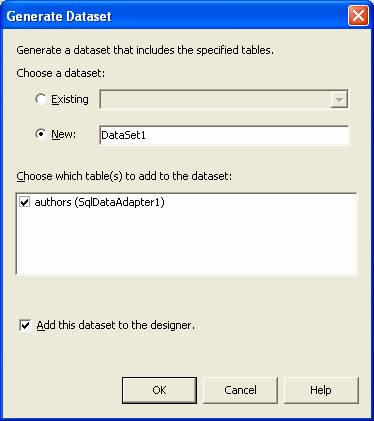
Figur 2: Dataset'tet genereres.
- Tilføj to almindelige kontroller til formen: En Button-kontrol (med default-navnet Button1) samt en DataGrid (med default-navnet DataGrid1).
- Skriv følgende kode i Button1s Click-event procedure:
SqlDataAdapter1.Fill(DataSet11)
DataGrid1.DataSource = DataSet11.Tables("authors")
System.Windows.Forms.MessageBox.Show(DataSet11.authors(0).au_fname)
SqlDataAdapter1.Fill(DataSet11);
DataGrid1.DataSource = DataSet11.Tables("authors");
System.Windows.Forms.MessageBox.Show(DataSet11.authors[0].au_fname);
- Kør projektet og klik på knappen. Nu skulle der dels gerne dukke data op i tabellen samt blive vist en MessageBox svarende til figur 3.
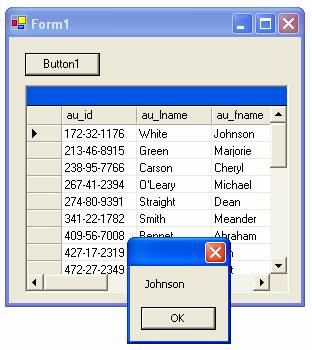
Figur 3: Det flot designede og meget avancerede user interface i aktion.
Hvad skete der egentlig her? Der skete det, at du fik lavet en særdeles dårligt konstrueret applikation til visning af data fra en database! Ja så - ja, det kan meget vel være, men hvad skete der egentligt?
Jo, det der skete var, at
- ved tilføjelsen af SqlConnection1- og SqlDataAdapter1-objekterne til "komponent-kassen" blev der placeret en stak autogenereret kode i Form1. Denne kode kan ses ved at ekspandere "Windows Form Designer generated code"-regionen i formens kodevindue. Den autogenererede kode er ganske omfattende og indbefatter bl.a. instansiering og opsætning af connection- og dataadapter- objekter (herunder definition af connection-streng), instansiering af select-, insert-, update- og delete-commands samt definition af tilhørende SQL-statements og parameter-collections.
- Ved genereringen af datasettet (punkterne 4 og 5 i den strikkeopskriften ovenfor) blev der endvidere genereret kode til erklæring og instansiering af DataSet11-objektet. Udover denne kode blev der som sagt tilføjet en fil ved navn DataSet1.xsd. Denne fil indeholder et XML-schema til beskrivelse af de udvalgte data. Endnu en fil (der har navnet DataSet1.vb eller DataSet1.cs alt efter valgt sprog) blev føjet til projektet. Denne fil indeholder definitionen af en klasse ved navn DataSet1; en klasse der er en nedarvning af System.DataSet-klassen. Den nedarvede klasse er kort fortalt blevet udvidet med typestærke properties til tilgang til den valgte databasetabel samt dennes felter. Disse typestærke properties tillader, at man kan skrive kode som den følgende:
DataSet11.authors(0).au_fname
DataSet11.authors[0].au_fname
frem for de typesvage pendanter:
DataSet11.Tables("authors").Rows(0)("au_fname")
eller
DataSet11.Tables.Item("authors").Rows.Item(0).Item("au_fname")
hvis man foretrækker eksplicitte kald til Item-properties frem for brug af default-properties
DataSet11.Tables["authors"].Rows[0]["au_fname"]
Men hvorfor var det, at applikationen var dårligt konstrueret? Alt det ovenstående lyder da ellers, som om vi endelig har fået en dejlig simpel måde at lave database-tilgang på - en måde hvor vi ikke skal lave en masse indviklet kode ? ja en måde der endda gør det muligt at få typestærk adgang til tabeller og felter med alle de fordele som dette medfører.
Lad os tage mine reservationer og forbehold fra en ende af:
- Kode placeret i user interface laget
De to "objekter", der tilføjes til komponentkassen i strikkeopskriftens punkt 3, får automatisk sat en række properties så som ConnectionString for SqlConnection1 samt SQL-statements og tilhørende parameter objekter for de til SqlDataAdapter1 hørende command-objekter. Disse properties er meget specifikke for det konkrete database layout og det at de tildeles i user interface-laget (i dette tilfælde i en Windows-form) strider fundamentalt mod princippet om flerlags-arkitekturer, som jo ellers har været det fremherskende arkitekturprincip i de seneste mange år. Ønsker man at ændre connection-strengen (fordi databasen nu f.eks. ligger på en anden maskine) eller ønsker man at ændre i en af de eksisterende SQL-statements (fordi der er kommet et ekstra felt til, en betingelse skal tilføjes eller senere ændres eller et felt eller en tabel har ændret navn), skal man ind på alle de forme (eller andre designflader der måtte være tale om), hvor man har tilføjet sådanne databaseobjekter via drag-and-drop. Kode der er let at vedligeholde? Nej! Tværtimod et kodemæssigt mareridt!
Principperne om simpel indpakning af funktionalitet og abstraktion af implementation (i dette tilfælde af database tilgang), som jo ellers har været en kodemæssig grundlov siden Anders Hejlsberg var dreng, er blevet tilsidesat på det groveste. Beslutter man sig til at ændre strukturen på den underliggende database, er man virkelig på den, idet der må tilregnes større rettelser på samtlige forme / designflader i applikationen.
- Generering af store mængder kode
Men er det så til gengæld ikke smart, at vi kan få genereret en hel masse kode ganske simpelt. Nej, det er det ikke! - i hvert fald ikke som hovedregel. Der har ind imellem været en tendens til at måle fremskridt i et softwareprojekt på mængden af koden i projektet. Men det er ikke noget godt mål i sig selv - jeg vil endda gå så langt som at sige, at alt andet lige foretrækker jeg, at et projekt indeholder så få linjer kode som muligt (naturligvis med måde - koden skal trods alt være forståelig og ikke blot en kryptisk samling af minimalistiske hacks). Små mængder af kode er (igen alt andet lige) simplere at vedligeholde end store mængder af kode. Så det, at vi ved at lave en simpel drag-and-drop kan få genereret store mængder af database kode, er ikke i sig selv godt, og når koden så endda ligger placeret i, hvad der burde være et rent brugergrænseflademæssigt lag, er det tæt på at være en katastrofe. Kode generering er et helt emne i sig selv, så ovenstående udsagn kan naturligvis nuanceres en hel del... ;^ )
Stærkt typet data-tilgang
Men hvad så med det stærkt typede dataset? Det er da smart - er det ikke? Selve det at arbejde typestærkt er som oftest bedre end at arbejde typesvagt eller endog typeløst. Endnu smartere er det dog at tænke generelle tanker og f.eks. lave data-drevne applikationer, hvor der skabes en kodemæssig uafhængighed af det konkrete indhold af database-tabellerne. Men er den kode, man laver specifikt rettet mod konkrete tabeller og felter, har en typestærk adgang til disse, unægteligt nogle særdeles markante fordele i form af typecheck på kompileringstidspunktet og understøttelse i udviklingsværktøjet i form af intellisence.
- Stærkt typede datasets er datasets
Personligt er jeg dog ikke specielt vild med lige præcis den måde, hvorpå de stærkt typede datasets er implementeret i Visual Studio .NET. Normalt vil jeg foretrække at opfatte stærkt typede databærende objekter som repræsentanter for de underliggende domæne-objekter (hvad Microsoft kalder Business Entities). Men Visual Studios stærkt typede datasets er ikke rene Business Entititeter. De er datasets. Det er hele pointen ved nedarvning: Subklassen (eller den afledte klasse om man vil) er superklassen (eller basisklassen om man også vil). Så en ansat-klasse må (få lov til at) nedarve fra en person-klasse, hvis en ansat-instans i alle de for det nærværende system relevante aspekter er at opfatte som en person. I så fald er en ansat en person. Men det er strengt taget faktisk ikke tilfældet her, idet et stærkt typet person-dataset, der nedarver fra System.DataSet jo kommer til at være et dataset og ikke en egentlig Business Entitet. Det samme gælder for et ansat-dataset, der også er en nedarvning af System.DataSet og som derfor også er et dataset (og ikke en person). Nuvel nogle vil sikkert mene, at der er tale om en ret søgt indvending set fra en pragmatisk synsvinkel. Men der er tre meget praktiske følger af denne måde at benytte "objekt-orientering" på:
- Problem #1: Nedarvning understøttes ikke
Det ene praktiske problem er, at den ovenfor demonstrerede kode-generering ikke i sig selv understøtter nedarvning, hvorved det ikke umiddelbart kan udtrykkes, at en ansat er en person. I sandhedens tjeneste skal det dog indrømmes, at noget i den stil vil kunne implementeres - men særligt kønt bliver det nu ikke.
- Problem #2: Modifikationer af den genererede kode
Det andet praktiske problem er, at når man laver stærkt typede klasser til repræsentation af Business Entiteter er det ofte, fordi man ønsker at kunne indlejre forretningslogik i klasserne. Sådan at eksempelvis det at sætte værdien af en CprNr-property automatisk fører til check af om CprNr'et er lovligt i forhold til f.eks. modulus-11-reglen. Et sådan check er ganske vist simpelt at indlejre i et stærkt typet person-dataset (det er blot at ændre i den kode-genererede person-dataset klasse). Men desværre vil en sådan modifikation af den kodegenererede klasse gå tabt den næste gang, dataset'tet måtte blive genereret (f.eks. efter ændring af den underliggende database-tabel). En typisk måde at håndtere det, at man ønsker at foretage modifikationer af genereret kode på er, at man ligger sådan modificerende kode i en sub-klasse til den genererede klasse. Man tilgår så ikke den genererede klasse direkte i ens applikation, men i stedet denne sub-klasse. Herved vil en gentagen kodegenerering ikke overskrive (læs: slette) ens modifikationer. Måske ikke den kønneste løsning, men en løsning man kan vælge at benytte sig af. Blot ikke i forbindelse med de af Visual Studio genererede stærkt typede-datasets. Her er man reelt set afskåret fra denne mulighed af flere grunde - bl.a. fordi properties'ene ikke er erklæret som værende virtuelle (VB: Overridable, C#: virtual).
- Problem #3: Forurenede interfaces på den genererede klasse
Og endelig er det tredje praktiske problem, at de programmeringsmæssige interfaces på de genererede stærkt typede datasets ikke er rene af natur. I sagens natur er et person-dataset "forurenet" med en masse members (metoder og properties - ja endda enkelte events), som ikke har en døjt med personer at gøre, men som stammer fra personens superklasse: System.DataSet. Om ikke andet anser jeg mængden af members, der dukker op, når intellisense viser "List Members"-listboksen, for unødigt forvirrende og rodende. Når jeg eksempelvis vil tilgå en CprNr-property, ønsker jeg ikke at skulle filtrere en masse (i denne sammenhæng) irrelevante dataset-members fra.
De stærkt typede datasets er hverken fugl eller fisk: De er ikke virkeligt stærkt typede fordi, at man stadig kan tilgå dataset?tet direkte og fordi, at man reelt set ikke kan ændre på implementationen af de stærkt typede properties (mht. den bagvedliggende datarepræsention, validering etc.).
Igen skal jeg i sandhedens tjeneste medgive, at man kan benytte og generere stærkt typede datasets - uden at involvere drag-and-drop af kode-genererende kontroller ind i design-containere - ved at lave de nødvendige og ønskede XML-schemaer manuelt eller med et andet værktøj - eller man kan for den sags skyld slette data-kontrollerne fra design-containerne efter at have genereret XML-schemaerne således, at drag-and-drop eksercitsen kun tjener til at generere et udgangspunkt for generering af de stærkt typede datasets. På denne måde undgår man trods alt at forbryde sig mod flerlags-modellernes arkitektur guide-lines, men som det vist med al tydelighed fremgår, er jeg i det hele taget noget skeptisk overfor de stærkt typede datasets.
Mange glimrende alternativer
Der er mange forskellige - og glimrende - måder man kan vælge at skrue sit database-lag sammen på: Man kan vælge, at benytte sig af ganske almindelige datasets returneret fra et Data Access Layer (de såkaldte DAL'er), eller man kan vælge at benytte sig af en eller anden form for typestærk indpakning. En sådan indpakning kan man vælge at lave selv - manuelt eller kodegenereret vha. et selvudviklet værktøj. Ønsker man at benytte sig af et kodegenereret database-lag, bør man nok først undersøge de kommercielle produkter (de såkaldte objekt-relationelle mapping-værktøjer), der findes på markedet, idet det at lave en (velfungerende) generel databaselags-generator langt fra er nogen triviel opgave. Microsoft er i øvrigt også selv i gang med at lave et sådan generisk database-lag til implementation af stærkt typet databasetilgang - de såkaldte Object Spaces.
Som jeg startede med at understrege, er ADO.NET korrekt anvendt en fremragende teknologi til implementation af database tilgang - hold dig blot fra at benytte Visual Studios stærkt typede datasets. Husk: Der er en måde at lave database tilgang på, der virker i alle situationer, og som giver gode resultater: God gammeldaws kode...